
基本原理
K-Means 作为一种最简单的聚类算法,在数据挖掘中有着比较广泛的应用。如下图所示,给你一批数据(绿色的点),让你将数据划分成2类,这就是K-Means要解决的问题。
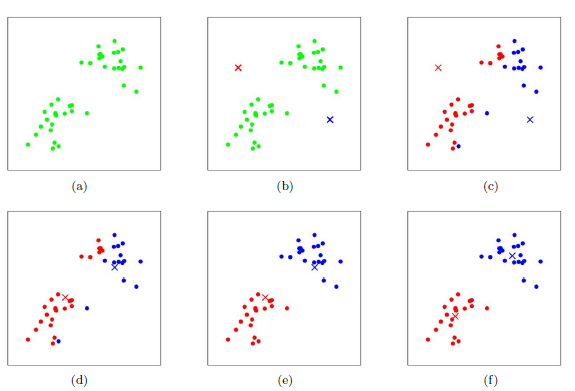
总的来说,K-MEANS的具体计算方法可分为如下的四步
- 随机选取K个中心点
图(b) - 遍历所有数据,将每个数据划分到最近的中心点
图(c)(d)(e) - 计算每个聚类的平均值,并作为新的中心点
- 重复上述过程,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
图(f)
在运用K-MEANS算法时,一般会对数据进行一定的预处理,例如对数据进行0-1归一化或PCA降维等操作。
时间复杂度: $ O(i n k m) $
空间复杂度: $ O(n m) $
其中$k$是需要聚类的数量,$m$为每个元素属性个数(向量的维度),$n$为数据量,$i$为迭代次数。一般均可认为是常量,所以时间和空间复杂度可以简化为$O(n)$,即线性的复杂度。
距离的种类
在第二步中要将每一个数据划分到最近的中心点对应的分类中,这里面涉及到距离的计算。一般来说,我们会用到一下几种距离:
欧氏距离
欧氏距离容易理解,就是两个点间直线的距离,其计算公式为
$$
d = \sqrt{(x-y)^2} = \sqrt{\sum_{i=1}^m (x_i -y_i)^2}
$$
曼哈顿距离
曼哈顿距离也叫城市街区距离,它的距离是每一个维度上的距离之和。对于二维平面来说,两个点的距离就是你只能走横线和竖线所需要的距离。其计算公式如下
$$
d = \sum_{i=1}^{m} |x_i -y_i|
$$
闵可夫斯基距离
事实上,上面两种距离只是闵可夫斯基距离的一种特例。闵可夫斯基距离定义了一组距离,通过改变参数$\lambda$就可以得到不同的距离表示,其计算公式如下
$$
d = (\sum_{i=1}^{m} (x_i -y_i)^{\lambda}) ^{\frac{1}{\lambda}}
$$
通过这里可以看出,上面两个距离就是当$\lambda =2 ,\lambda =1$时的闵可夫斯基距离。
K-MEANS的缺点
K-Means主要有两个最重大的缺点,都和初始值有关:
- 第一个问题是初始聚类中心的选择问题,由于初始的聚类中心是完全随机的并且不同的聚类中心会带来完全不同的聚类结果,因此这个因素大大影响着K-MEANS的效果。
- 聚类数量K要求事先给定。在大部分情况下,由于数据维度很高,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。
初始聚类中心
多次运行
一种解决初始聚类中心选择问题的方案就是多次运行聚类算法,并将每次的结果记录下来,最后选择的结果较好的那一组。结果的衡量标准是聚类后每一个类别的总平方和,叫做误差平方和SSE其中SSE定义为
$$ SSE = \sum_{i=1}^K \sum_{x \in \omega_i} |x-u_i|^2$$
其中
$$u_i = \frac{1}{N_i} \sum_{x \in \omega_i} x $$
其中 $ \omega_i $ 表示第$i$个类的集合,$u_i$ 是第$i$个聚类的平均值。
K-MEANS++算法
为了更好的解决初始聚类中心问题,有人提出了K-MEANS++算法,其主要思想就是让初始的聚类中心之间的相互距离要尽可能的远。
- 从输入的数据点集合中随机选择一个点作为第一个聚类中心
- 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)之和
- 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
- 重复2和3直到k个聚类中心被选出来
- 利用这k个初始的聚类中心来运行标准的k-means算法
这种方法可以选出K个距离比较远的中心,不过为什么这样子K-MEANS的效果就比较好,这里面貌似设计到很复杂的数学证明,就不再具体阐述了。
聚类数量K的选取
在这里,介绍一种通过重复运行选取较好的K的方式。事实上,对于聚类数量K选取也有ISODATA算法,但其中的原理比较复杂,在这里不做介绍了。
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。其具体的计算如下:
- 对于第$i$个元素$x_i$,计算$x_i$与其同一个簇内的所有其他元素距离的平均值,记作$a_i$,用于量化簇内的凝聚度。$a_i = \frac{1}{N}\sum_{j=1}^{N}d(x_i,x_j)$
- 选取$x_i$外的一个簇$b$,计算$x_i$与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作$b_i$,用于量化簇之间分离度。$b_i = \min\limits_{b} { \frac{1}{N_b}\sum_{j=1}^{N_b}d(x_i,x_j)}, x_j \in \omega_b$, 其中$N_b$表示类别b中的元素数量
- 对于元素$x_i$,轮廓系数 $s_i = (b_i – a_i)/max(a_i,b_i)$
- 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
$$ SC=\frac{1}{N} \sum_{i=1}^{c} \sum_{j=1}^{N_i} s_j $$
其中$N$表示所有的元素总量。从上面的公式,不难发现若$s_i$小于0,说明$x_i$与其簇内元素的平均距离小于最近的其他簇,表示聚类效果不好。如果$a_i$趋于0,或者$b_i$足够大,那么$s_i$趋近与1,说明聚类效果比较好,由此可以用来确定聚类数量K值的选取。
在实际应用中,由于K-Means一般作为数据预处理,或者用于辅助分类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次K-Means(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的$k$作为最终的聚类数量。
